AMEZING77
[TOC]
SQL SERVER Tutorial
- 创建时间: 2024年12月19日 21:35
- Tag: Website
- Link to Youtube
- Link to website
- 一些杂项

Connecting to SQL Server
- 通过SSMS连接数据库
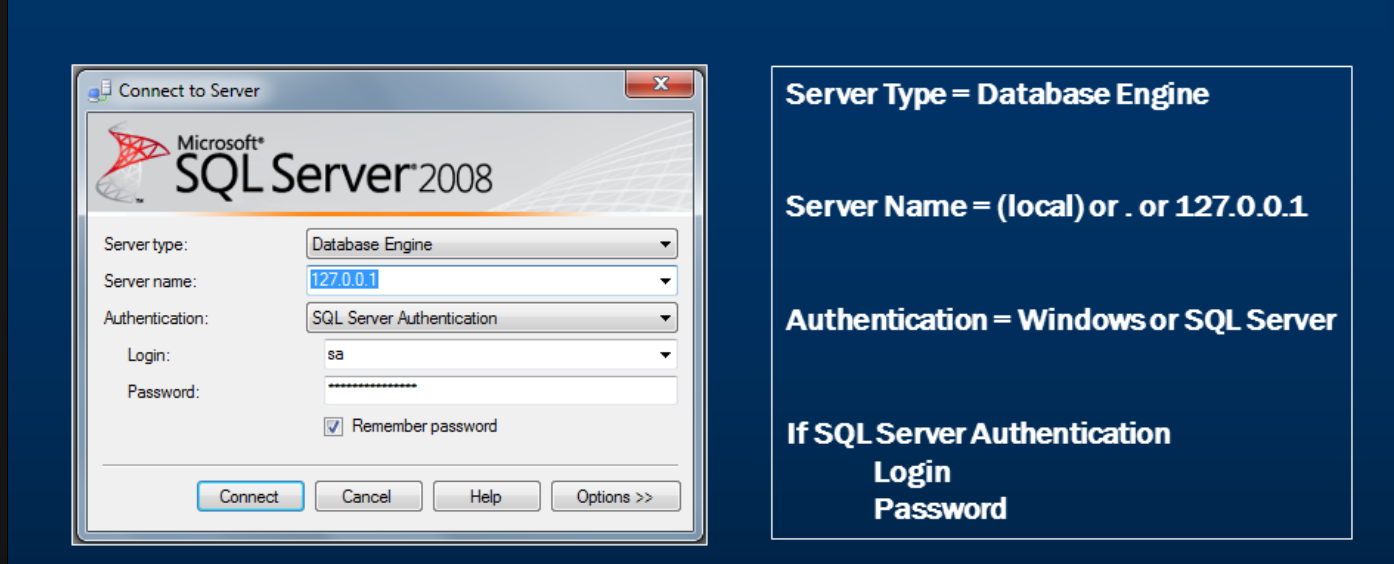
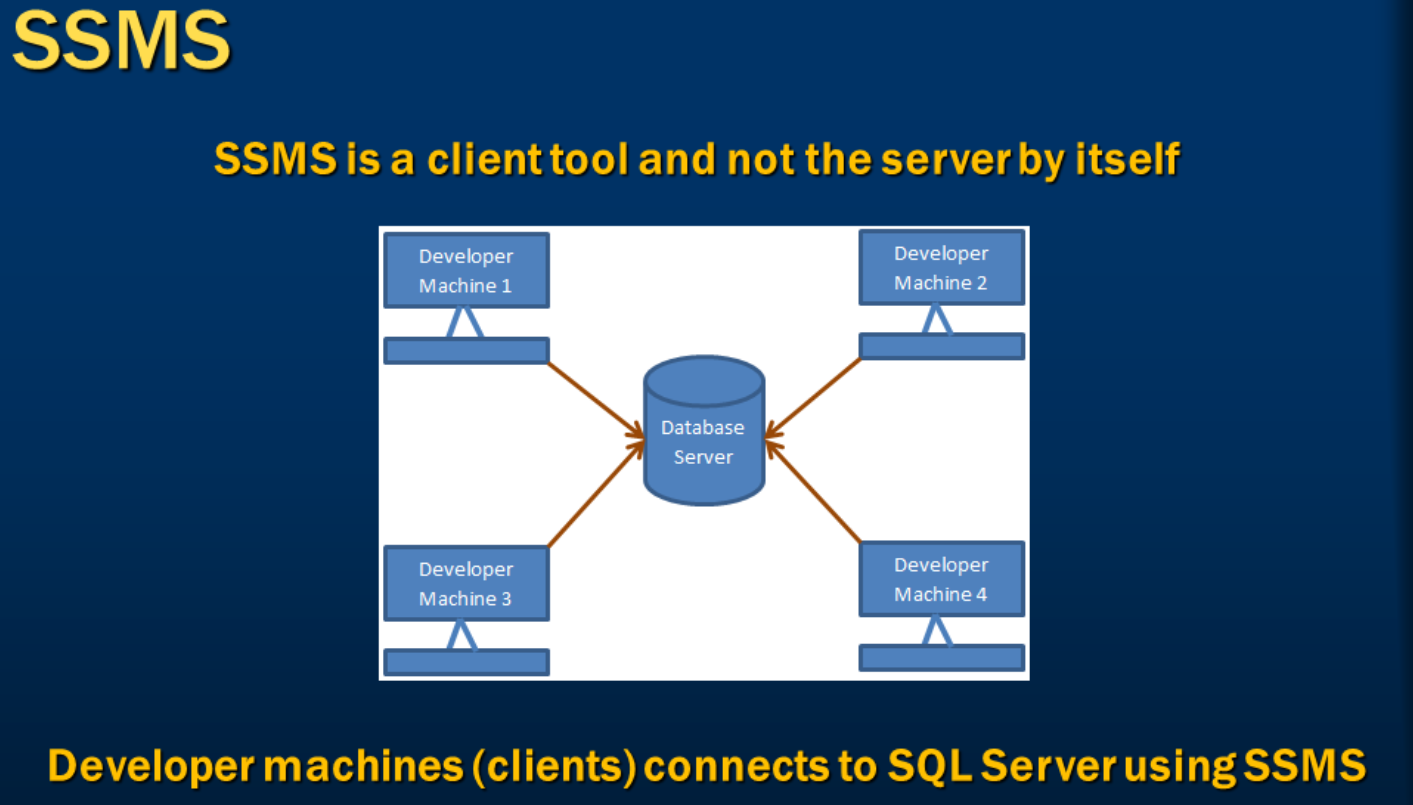
- 什么是SSMS
通过本地的SSMS来连接(本地/远端)数据库
 —
—
数据库操作
- 创建数据库
Create DataBase 数据库名称; - 创建数据库会生成两个文件.mdf和_log.ldf

- 修改数据库名称
Alter DataBase 数据库名称 Modify Name= 新数据库名称; Execute sp_renameDB '数据库名称','新数据库名称'; - 删除数据库
Drop DataBase 数据库名称
- 如果数据库正在使用,断开链接,切换到其他数据库;
Put the database into single user mode.
Alter DataBase 数据库名称 Set Single_User With Rollback Immediate
建表操作
- 创建Table;
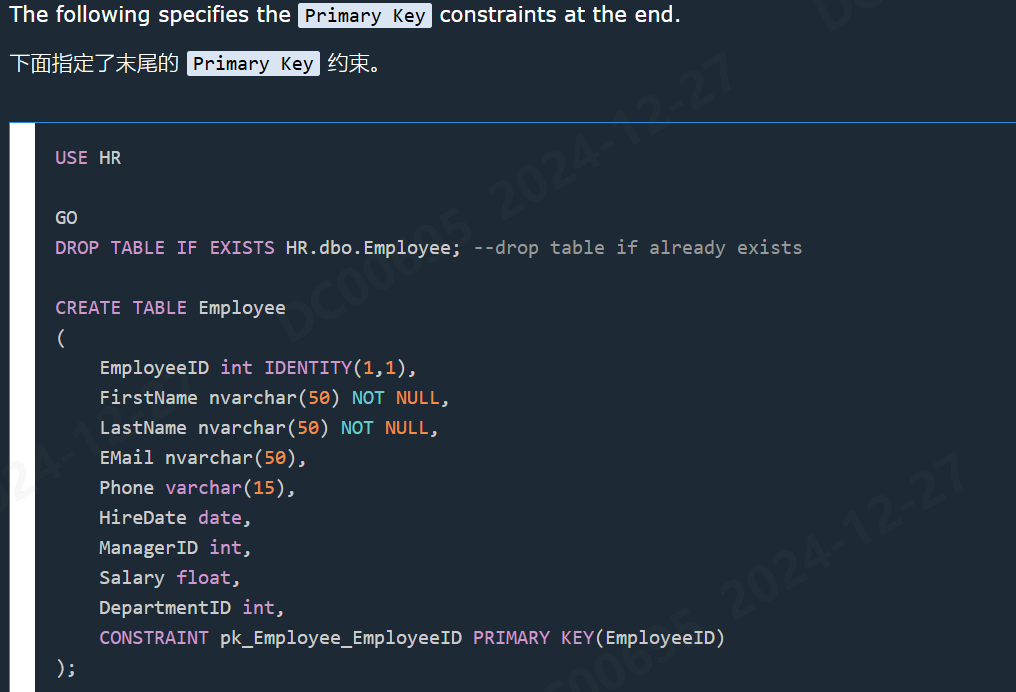
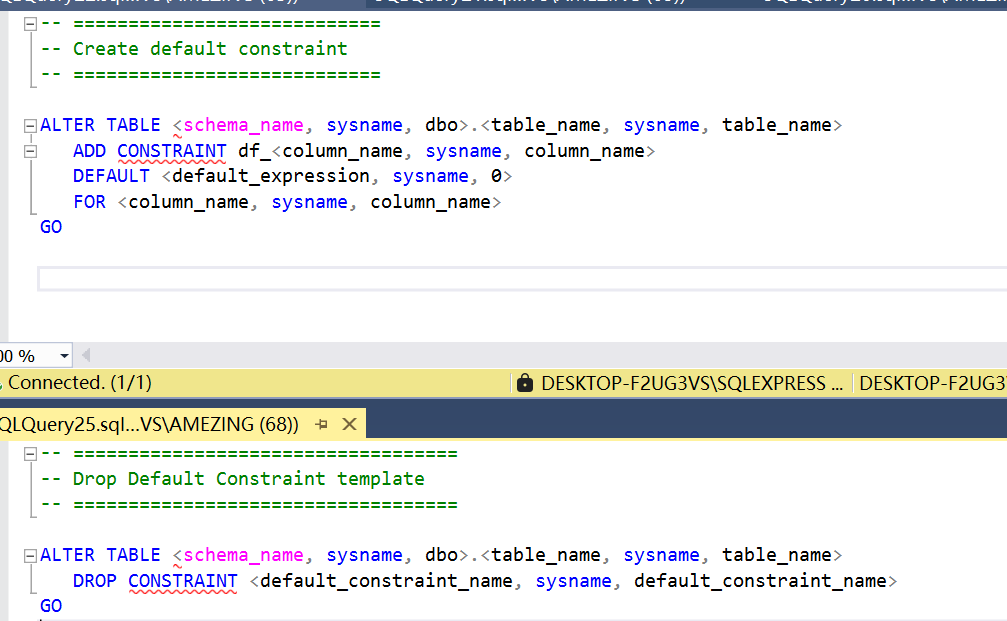
- 表中列设置默认值;
Alter table 表名 --创建列默认值 Add ColumnName 数据类型 Default 默认值; --修改列默认值 Alter Column ColumnName Set Default 默认值;
- 通过SSMS连接数据库
约束操作
- 在几种不同的情况下增加constraint

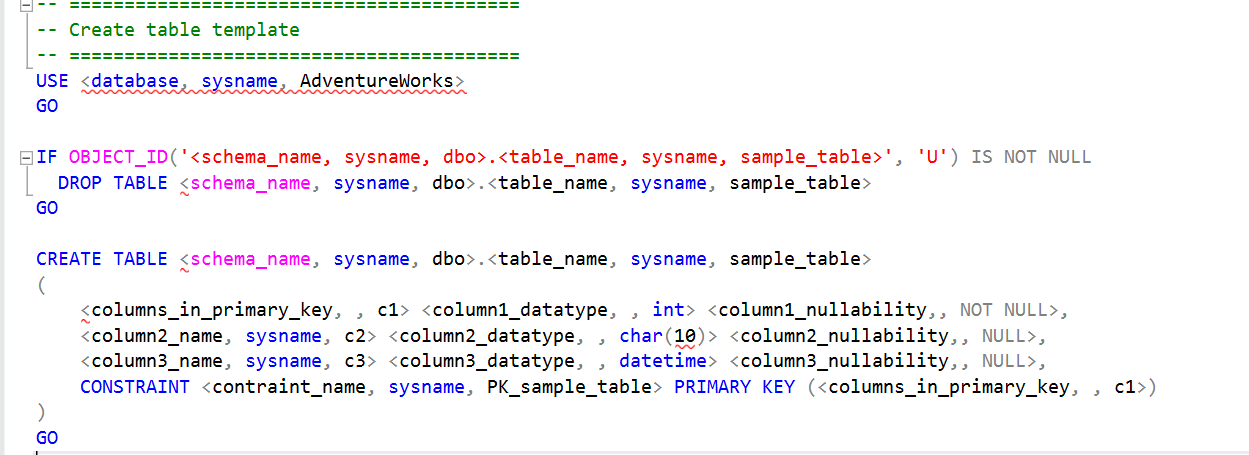
- SSMS提供的template
 —
—
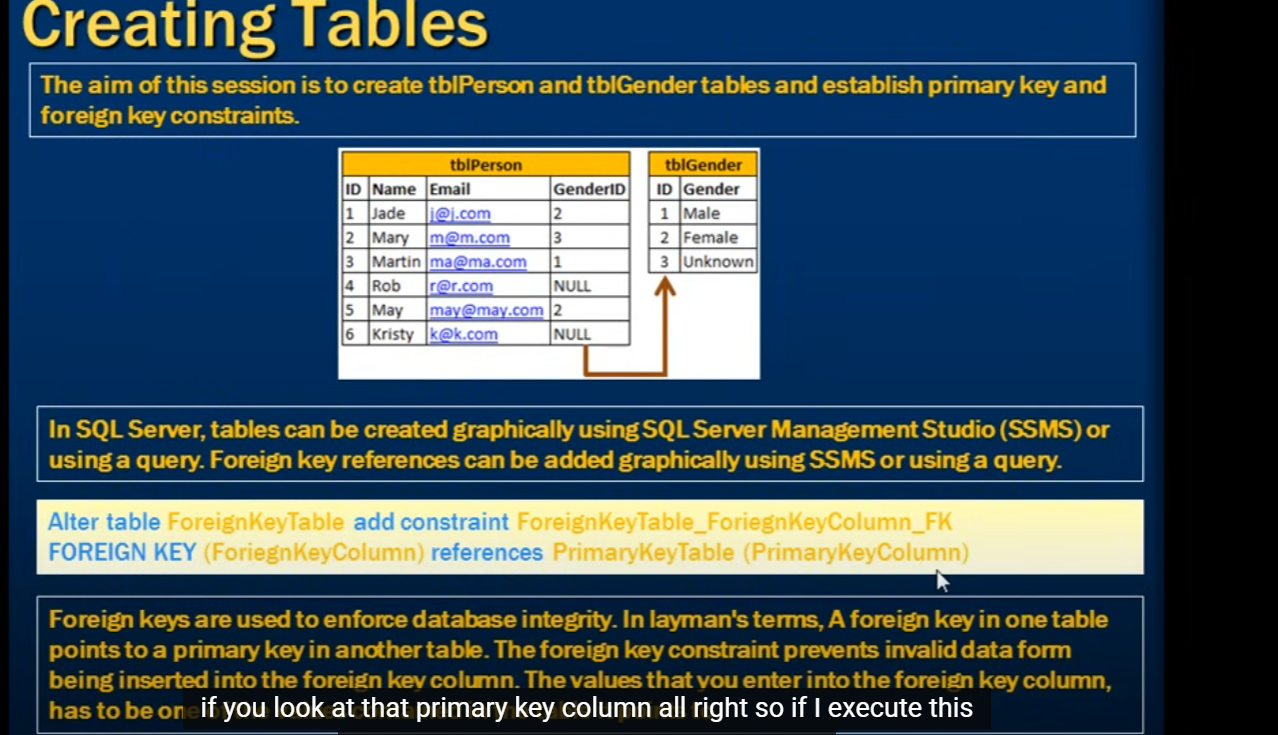
ForeignKey
- 建立外键约束
Alter table ForeignKeyTable add constraint FK_ForeignKeyTable_Column foreign key (Column) references PrimaryKeyTable(Column); - 为什么要使用外键约束

级联(**)
级联引用完整性(Cascading Referential Integrity)是一种数据库约束,用于维护表之间的关系一致性。
当主表中的记录被更新或删除时,级联操作会自动更新或删除引用表中的相关记录。
这样可以确保数据的一致性和完整性。
- 为什么要使用级联引用完整性?

- 几种默认的Action
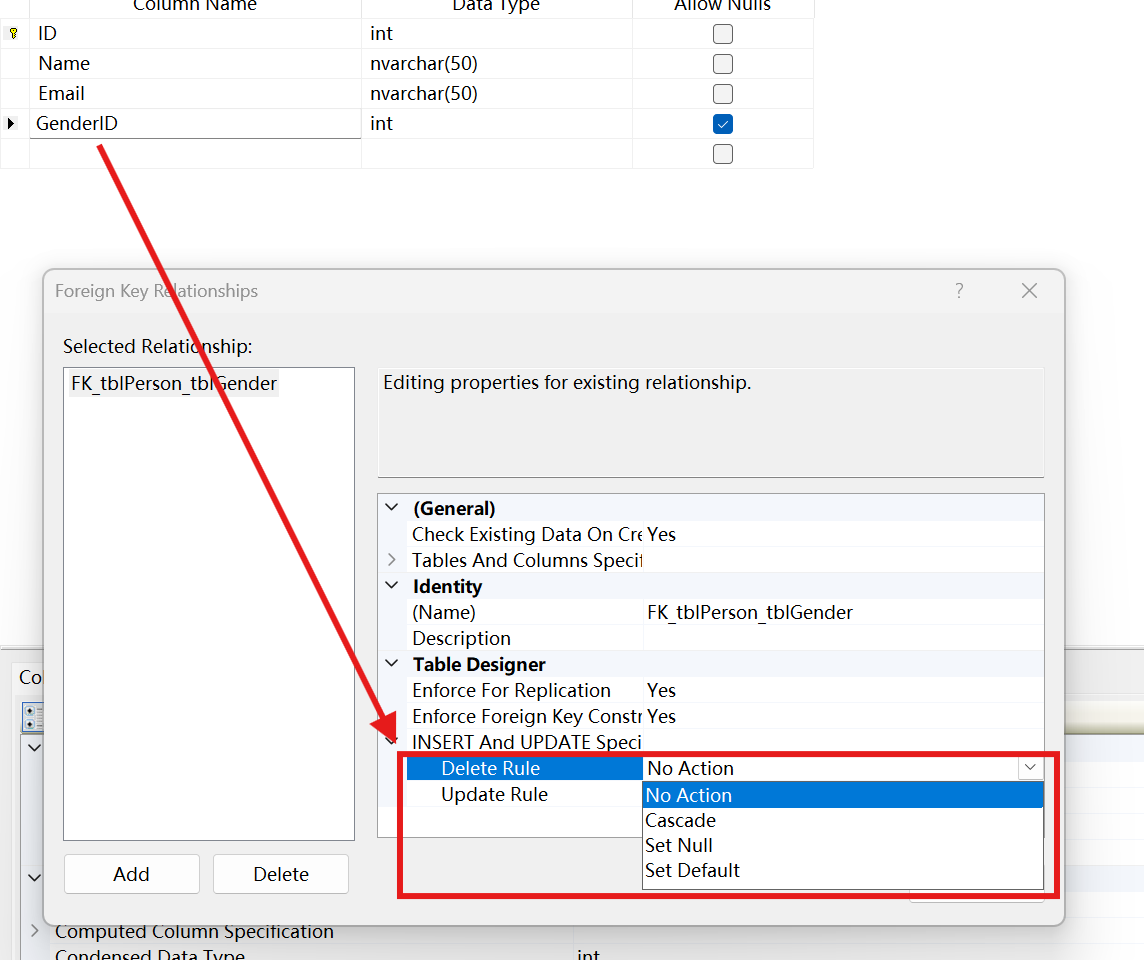
- 如何理解外键约束的几种配置操作
在SQL Server中,外键约束可以配置几种默认的操作(Action),
这些操作定义了当主表中的记录被更新或删除时,引用表中的相关记录应该如何处理。
常见的操作包括:
NO ACTION:如果试图删除或更新主表中的记录,而引用表中存在相关记录,则操作会失败。这是默认行为。CASCADE:当主表中的记录被删除或更新时,引用表中的相关记录也会被自动删除或更新。SET NULL:当主表中的记录被删除或更新时,引用表中的相关记录的外键列会被设置为NULL。-
SET DEFAULT:当主表中的记录被删除或更新时,引用表中的相关记录的外键列会被设置为默认值。CHECK constraint
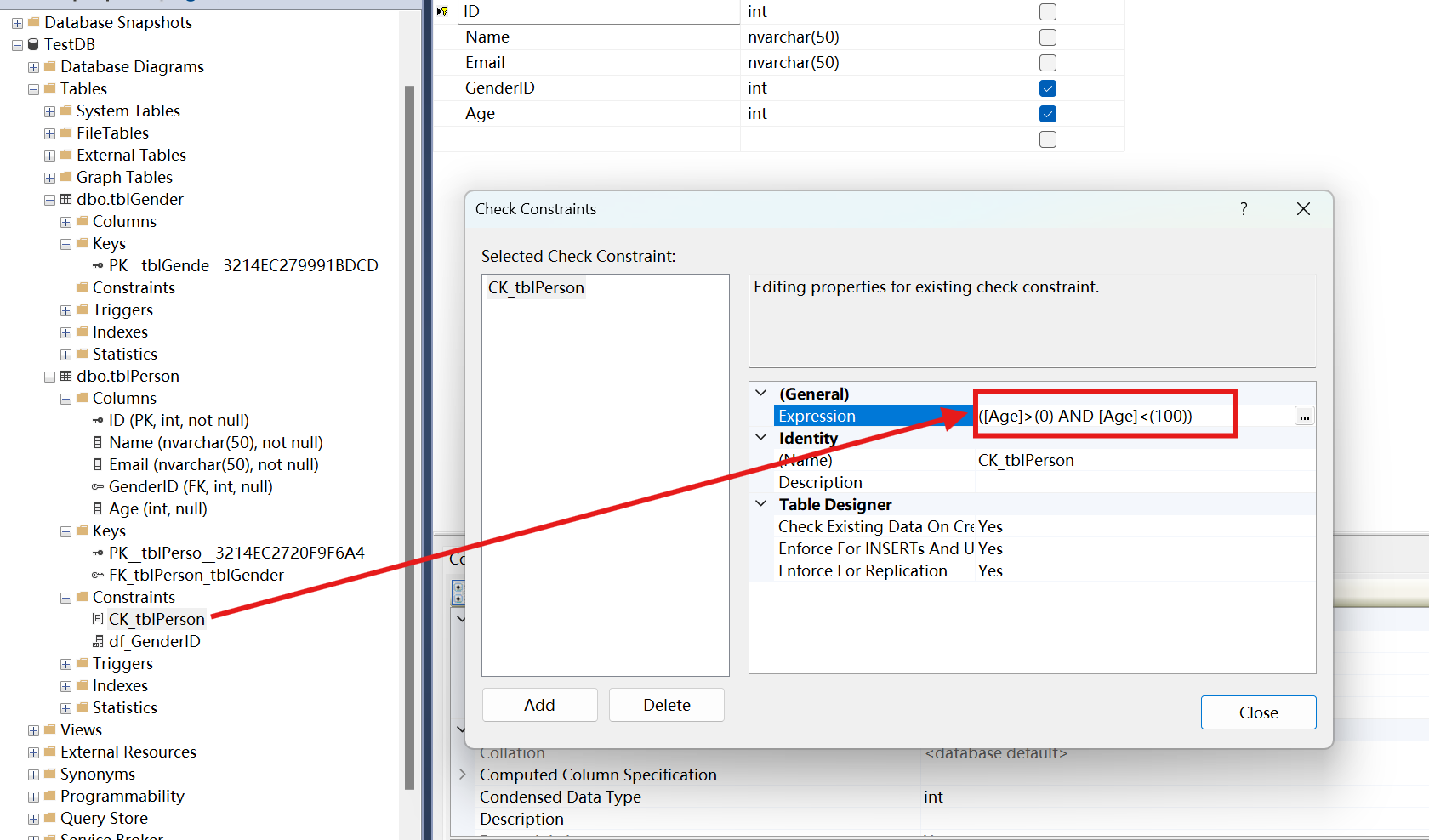
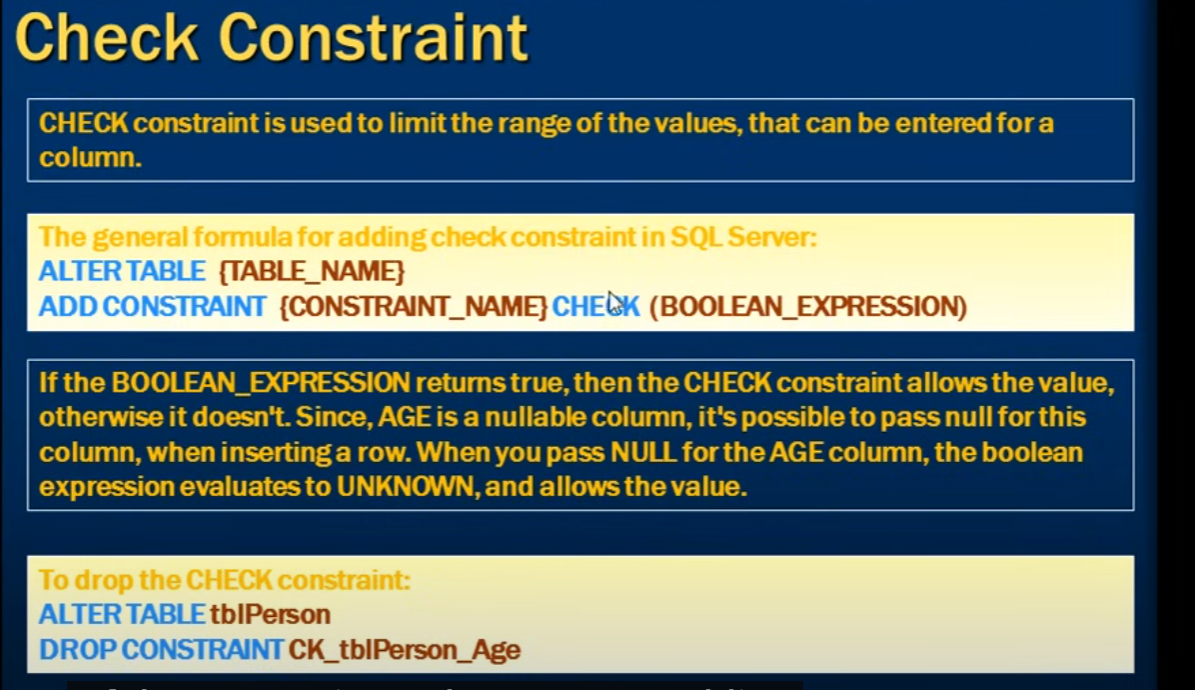
CHECK约束用于在插入或更新数据时验证列中的值是否符合指定的条件。 如果数据不符合条件,则插入或更新操作将失败。 CHECK约束可以应用于单个列或多个列
- 如何添加CHECK constraint
 —
—
Identity Column(***)
Identity列是一种特殊的列,用于自动生成唯一的标识符。 - 如何创建Identity Column
Create Table 表名( ID int Identity(1,1) Primary Key, ); - 重置Identity与获取
- 首先获取当前的种子值
SELECT IDENT_CURRENT('表名') AS CurrentIdentity; - 其次确认要重置的种子值不能与原有的冲突;
DBCC CHECKIDENT ('表名', RESEED, CurrentIdentity+1);
- 首先获取当前的种子值
- SCOPE_IDENTITY()与@@IDENTITY与IDENTITY_CURRENT(‘表名’)的区别
SCOPE_IDENTITY():返回在当前作用域内最后生成的标识值。(same session and same scope)@@IDENTITY:返回最后生成的标识值,不受作用域限制。(same session and any scope)-
IDENTITY_CURRENT('表名'):返回指定表的最后生成的标识值,不受作用域限制。(any session and any scope)UniqueKey constraint and PrimaryKey
- 设置单列UniqueKey

- 设置多列UniqueKey
Alter Table 表名 Add Constraint UK_表名_列名1_列名2 Unique (列名1, 列名2); - 注意事项

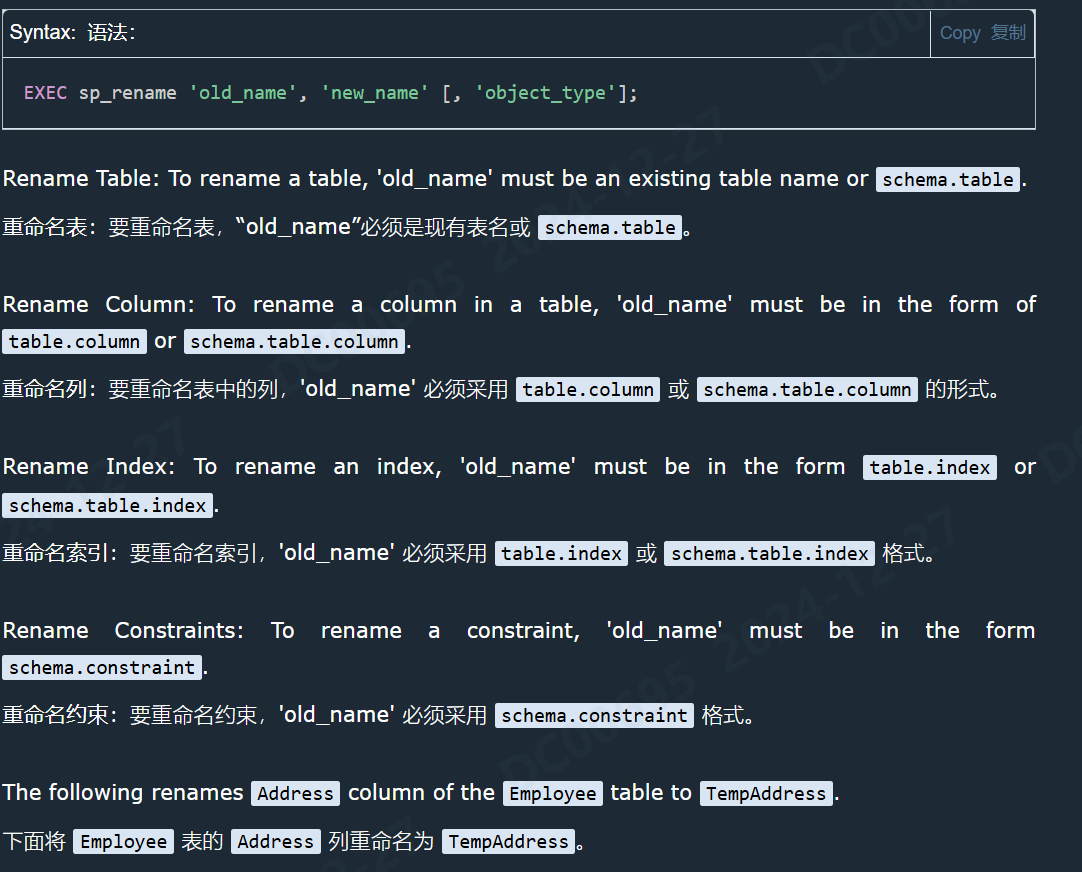
重命名表、列、约束
View
- 视图是一个虚拟的表,是一组查询语句的返回的表的 命名;
- 视图的几种类型;
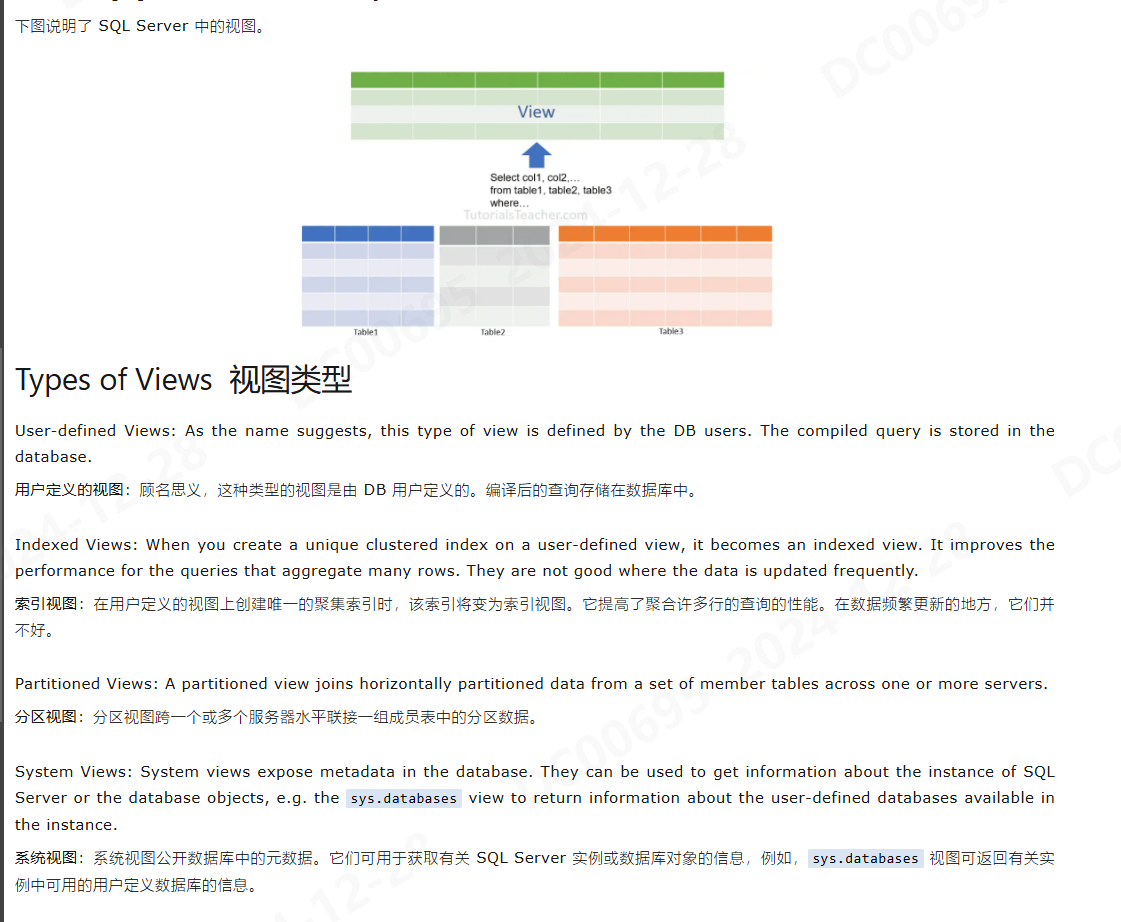
- 视图可以包含来自一个或多个表的数据,并且可以被当作普通表一样进行查询和操作;
- 建立和删除语句
CREATE/Alter VIEW <schema_name>.<view_name> AS SELECT column1, column2, ... FROM table1, table2,... [WHERE]; --删除视图 IF OBJECT_ID('dbo.EmployeeAddress', 'V') IS NOT NULL DROP VIEW dbo.EmployeeAddress;
Functions
System Functions
UDFs(User Defined Functions)
目的是为了创建可重用的代码块,分为两种类型; 1、返回单个值的标量函数(Scalar Function) 2、返回表或多行结果的表值函数(Table-Valued Function) 3、UDF 中的错误处理受到限制。UDF 不支持 TRY-CATCH、@ERROR 和 RAISERROR。
- Scalar Function
CREATE or ALTER FUNCTION GetAvgSalary(@DeptID int) RETURNS float --returns float type value AS BEGIN --declares float variable DECLARE @avgSal float = 0; -- retrieves average salary and assign it to a variable SELECT @avgSal = AVG(Salary) FROM Employee WHERE DepartmentID = @DeptID --returns a value RETURN @avgSal; END- Inline Table-Valued Function
CREATE or ALTER FUNCTION dbo.GetEmployeeList(@hiredate date) RETURNS TABLE AS RETURN SELECT * FROM Employee WHERE HireDate > @hiredate;- Multi-Statement Table-Valued Function
CREATE or ALTER FUNCTION dbo.GetSeniorEmployees() RETURNS @SrEmp Table ( EmpID int, FirstName varchar(50) ) AS BEGIN Insert into @SrEmp Select EmployeeID, FirstName from Employee; --delete other employees delete from @SrEmp where EmpID > 10; return end- 优点

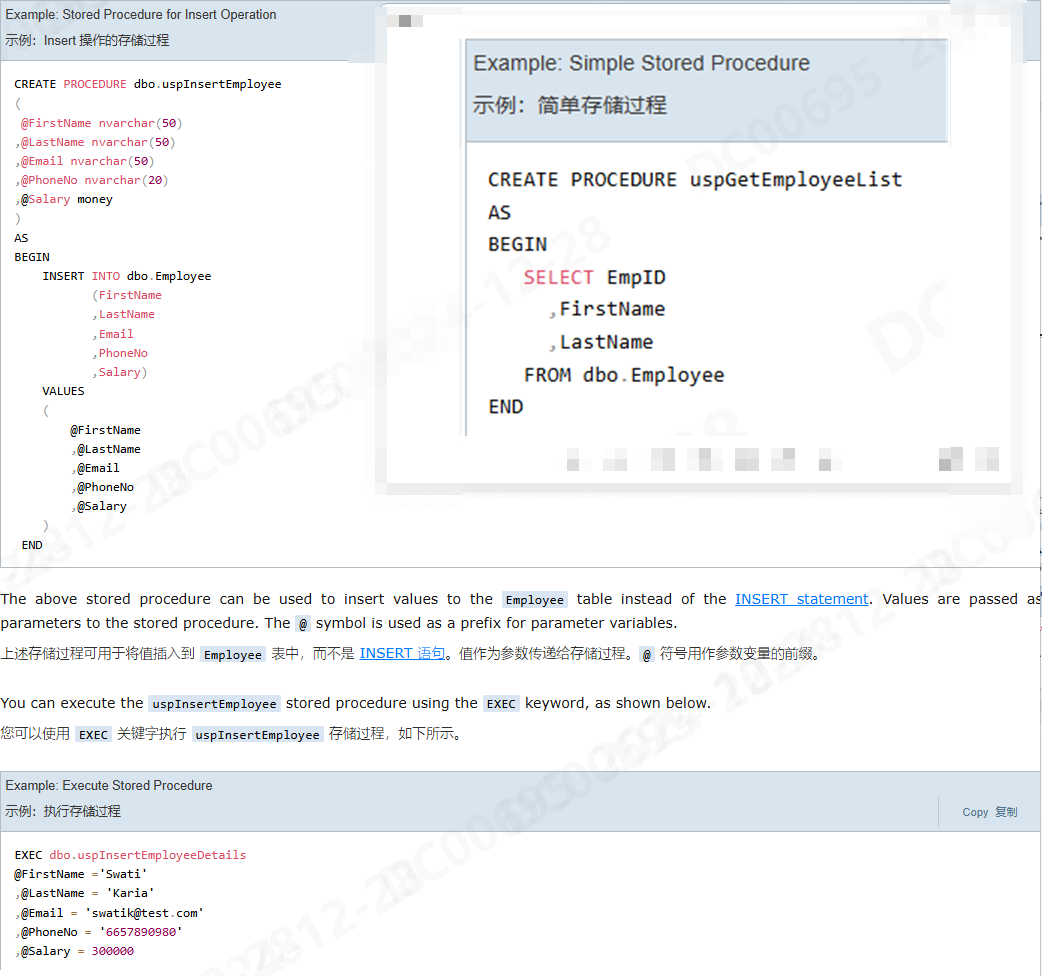
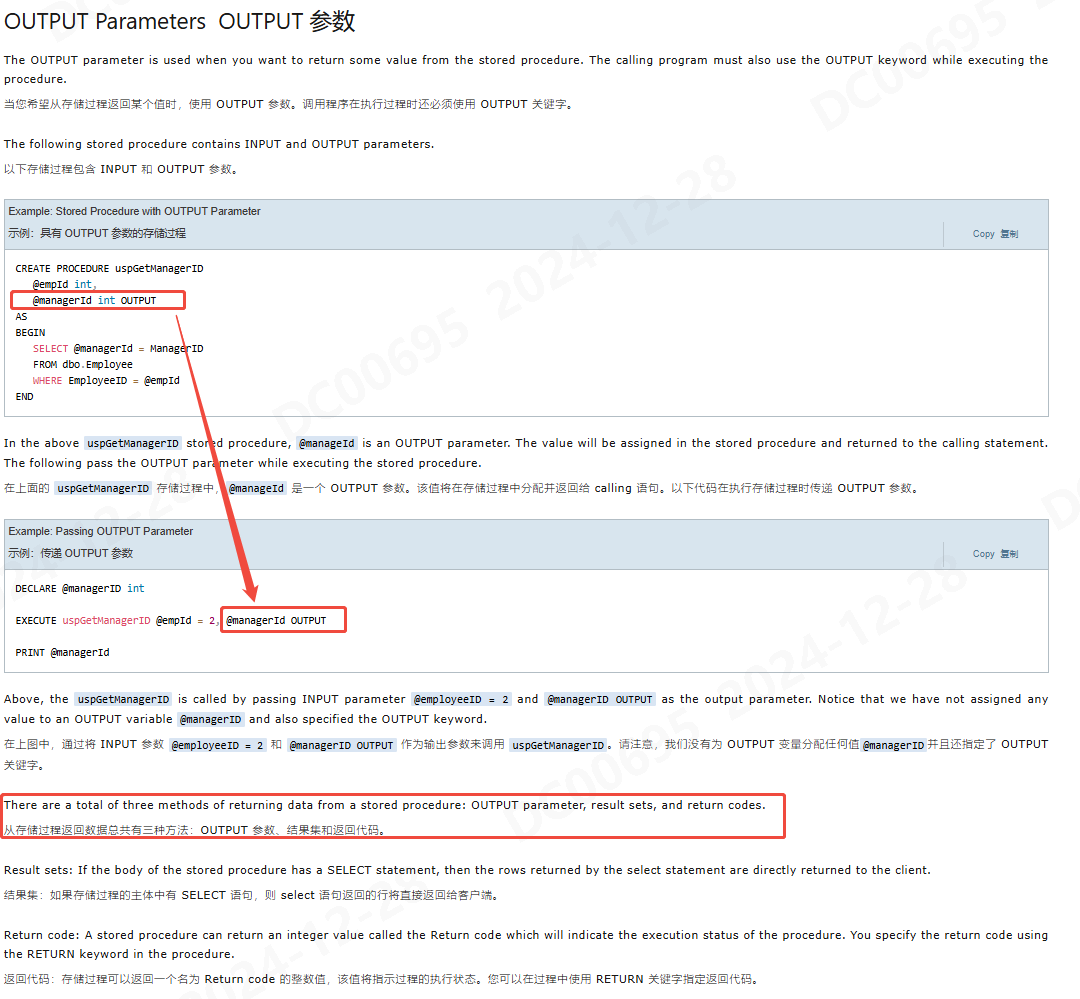
Stored Procedures
- 存储过程是一组编译并存储在数据库中的 T-SQL 语句。
- 存储过程接受输入和输出参数,执行 SQL 语句,并返回结果集(如果有)。
- 默认情况下,存储过程在首次执行时进行编译。它还会创建一个执行计划,该计划将重复用于后续执行,以提高性能。
- 命名,由于系统以sp_开头,建议用户自定义的以usp_开头;
- 已经定义的sp可以通过
sp_help spName来查看具体语句;- 几个关键语句;
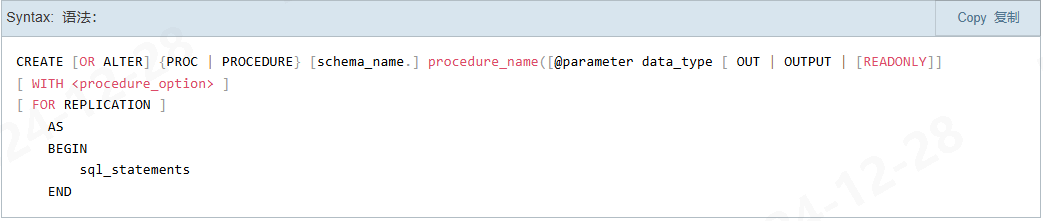
- 参数语法
- 输入参数和输出参数的区别
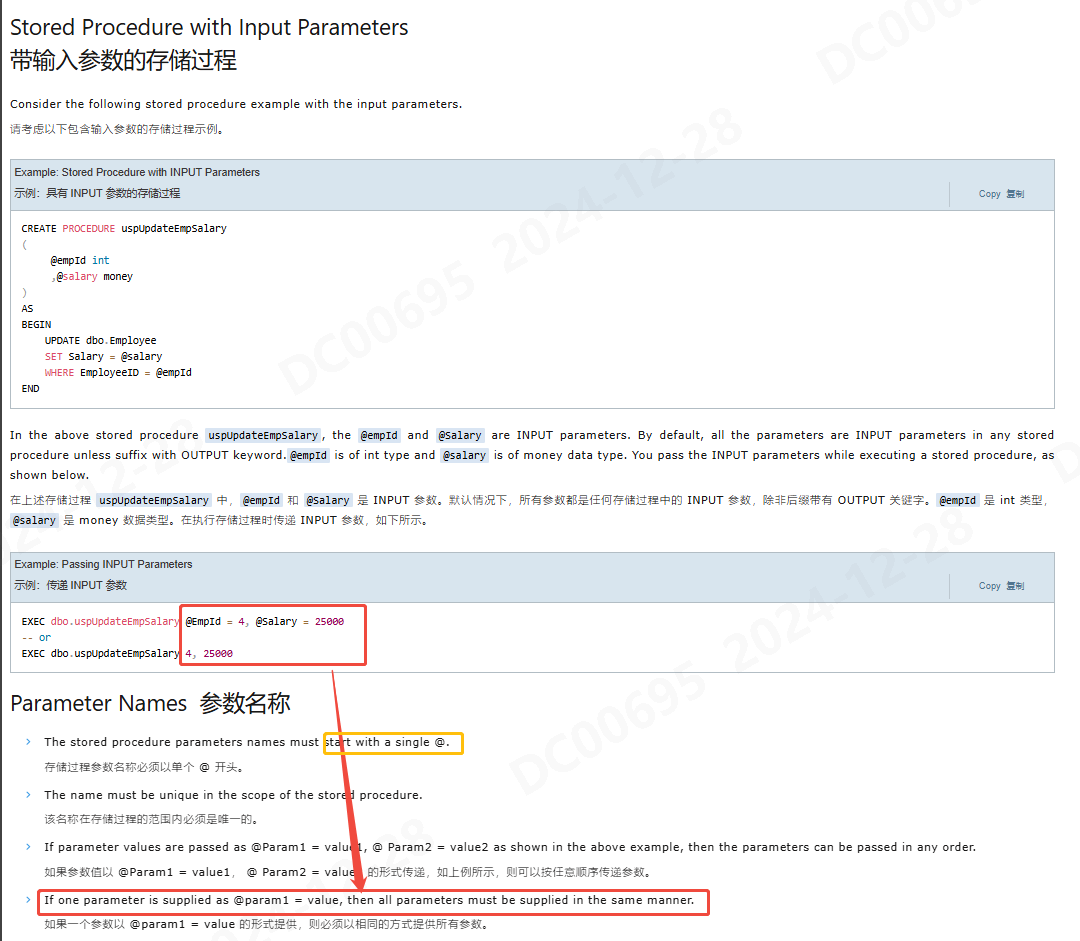
- 优点

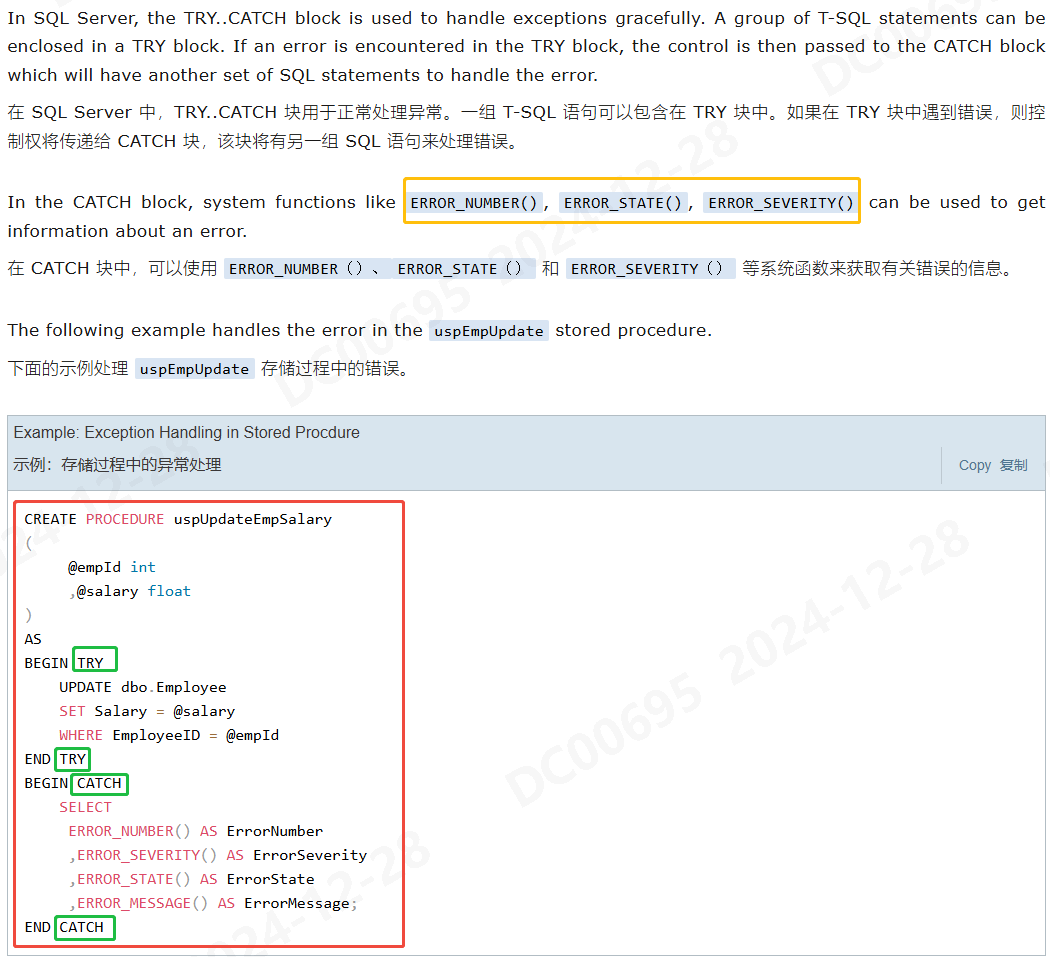
Try-Catch

INDEX
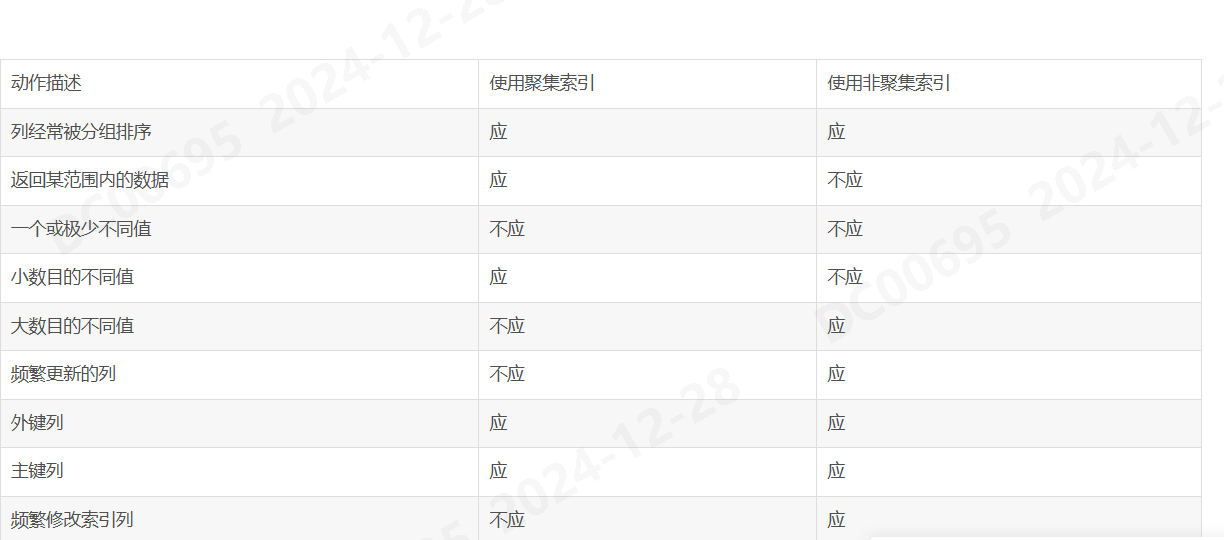
Clustered Index
- 聚集索引依托于表中经常用于Select/Where的单列/多列进行创建;
- 每个表只能有一个聚集索引;
- 聚集索引的键值决定了表中数据的物理存储顺序;
- 创建Primary Key的Constraint时,会自动创建一个聚集索引,且这种索引只能通过删除约束来间接删除;
- 应用聚集索引的优点;
- 由于原始数据表中的数据是按照Row的格式,无序存储在Heap中的,所以每次查询表,都需要遍历所有数据;
- 而聚集索引,改变了数据的物理存储顺序,使得查询效率大大提升;
- 聚集索引的理论基础是B树,增删改查的时间复杂度都是O(logn);
- Syntax
CREATE CLUSTERED INDEX CIX_TableName_ColumnName ON dbo.TableName(Col1 ASC, Col2 DESC)Non-Clustered Index
- 依托于表中的单列/多列,创建一个独立的数据结构,其中的值存储表中数据行的指针;
- 一个表中可以有多个非聚集索引;
- 非聚集索引不改变表中数据的物理存储顺序;
- 创建Unique Contraint 时,会自动创建一个非聚集索引,且这种索引只能通过删除约束来间接删除;
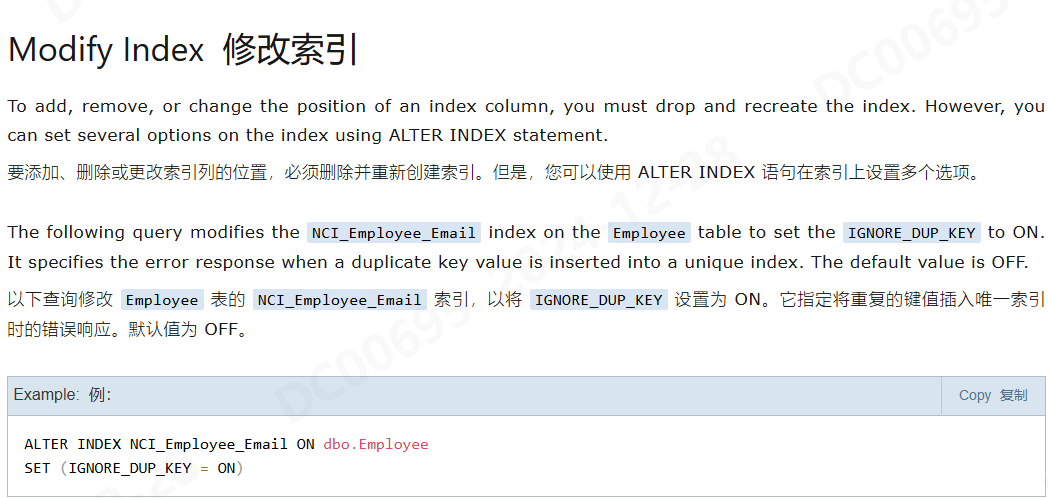
修改/删除索引
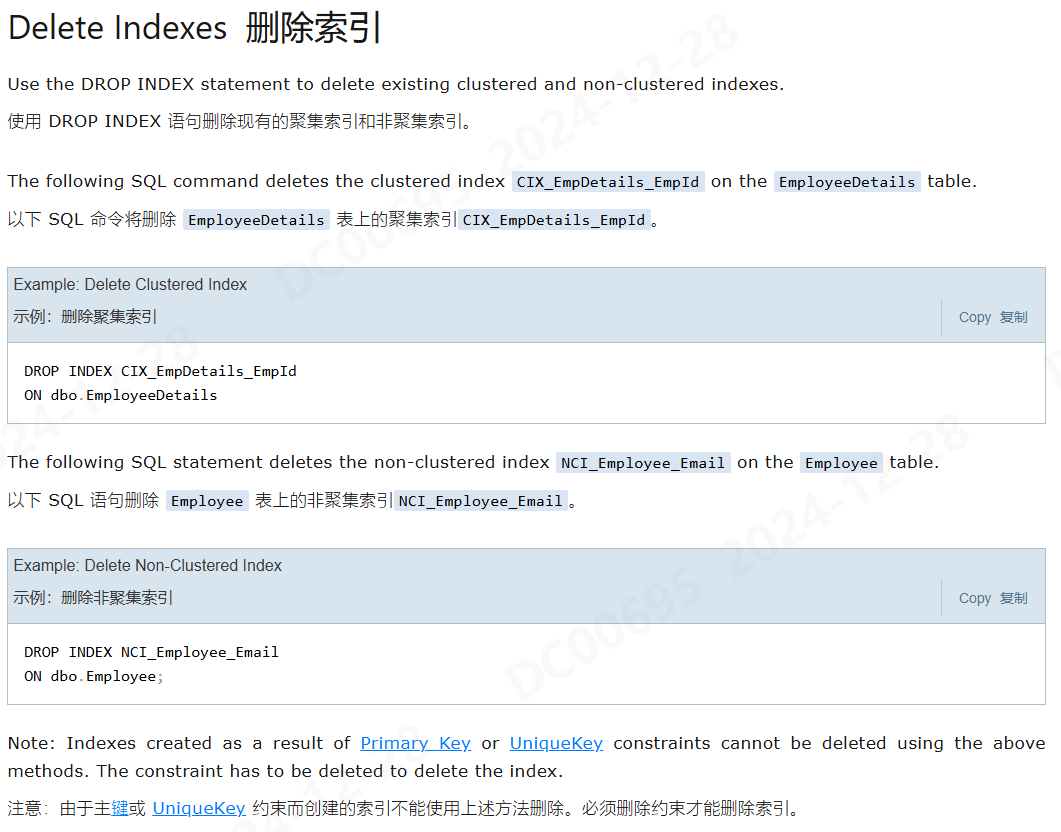
Transaction

- Begin Transaction
- Set Transaction
- Commit
- Rollback
- Saveponit
- Release Savepoint
BEGIN TRANSACTION tranName; SAVEPOINT SP1; Select Name FROM TableName; SAVEPOINT SP2; DELETE FROM TableName WHERE ID = 1; ROLLBACK TO SAVEPOINT SP1; COMMIT;
几个简单的数据库调优
